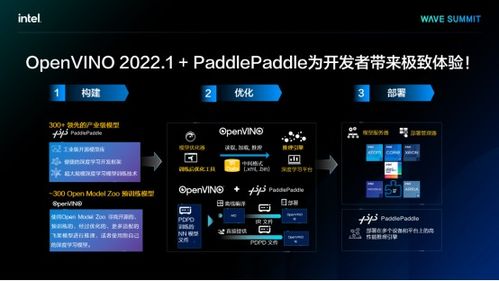
在人工智能技术飞速发展的今天,算力与算法已成为驱动其前进的双轮。作为全球半导体行业的领军者,英特尔不仅持续推动硬件算力的边界,更深刻认识到软件生态对于释放硬件潜能、加速AI普惠的关键作用。英特尔与百度飞桨(PaddlePaddle)的深度合作,正是“软硬协同”战略的典范,旨在从基础设施层面为人工智能的发展注入强大的“加速度”。
硬件基石:为AI计算提供澎湃动力
英特尔的硬件产品线,特别是至强(Xeon)可扩展处理器,已成为众多数据中心和AI工作负载的可靠基石。其内置的AI加速技术,如英特尔® 高级矢量扩展512(英特尔® AVX-512)以及集成AI加速的英特尔® AMX(高级矩阵扩展),能够显著提升深度学习训练与推理的效率。这些硬件创新旨在处理海量数据与复杂模型,为包括飞桨在内的AI框架提供了强大、通用且高效的算力支持。
软件优化:释放每一分硬件潜能
顶尖的硬件需要极致的软件优化才能发挥全部实力。英特尔与飞桨的合作核心便在于此。双方团队进行了深度的协同优化:
- 框架层优化:针对英特尔架构(IA),特别是至强处理器,对飞桨框架的核心算子、计算图编译与调度进行了全方位优化,确保计算任务能在英特尔硬件上以最高效的方式执行。
- 库函数强化:集成并优化了英特尔 oneAPI 深度神经网络库(oneDNN),这是一套性能经过极致调优的构建模块,用于深度学习应用。通过调用 oneDNN,飞桨能够直接利用英特尔平台的低层指令集优化,大幅提升卷积、矩阵乘法等关键操作的性能。
- 工具链赋能:借助英特尔® OpenVINO™ 工具套件,可以进一步优化经飞桨训练出的模型,并将其高效部署在从边缘到云端的各种英特尔硬件上,实现跨平台的高性能推理。
“软硬一体”的加速度价值
这种“软硬件双管齐下”的策略,为开发者与最终用户带来了切实的“加速度”:
- 性能显著提升:经过联合优化的飞桨在英特尔硬件上运行AI模型,相比未优化版本可获得显著的性能提升,意味着更短的训练时间和更高的推理吞吐量,直接降低了时间与计算成本。
- 开发体验简化:开发者无需深入了解底层硬件细节,即可通过熟悉的飞桨API,自动享受到针对英特尔架构的优化好处,从而更专注于算法与模型创新本身。
- 生态兼容与拓展:此举强化了飞桨在x86生态中的竞争力,也为英特尔庞大的硬件用户群提供了更优的AI框架选择,促进了开放、多元AI生态的繁荣。
- 赋能产业智能化:从智慧城市、智能制造到科学发现,性能与效率的提升使得更复杂、更精准的AI模型能够应用于更广泛的产业场景,加速千行百业的智能化转型进程。
共筑开放AI基础设施
英特尔与飞桨的合作,超越了简单的技术适配,是构建下一代人工智能基础软件栈的重要实践。它昭示着,在AI时代,真正的“加速度”源于硬件创新与软件优化的深度融合。通过携手打造更强大、更开放、更易用的底层基础,双方正共同为全球AI开发者与产业界夯实基石,驱动人工智能技术以更快的速度、更低的门槛渗透到社会的每一个角落,共创智能未来。